增强文本到图像生成网络安全性的框架
机器学习算法的出现,可以按照人类用户的指令生成文本和图像,为低成本创建特定内容开辟了新的可能性。一类正在从根本上改变全世界创意过程的算法是所谓的文本到图像(T2I)生成网络。
T2I人工智能(AI)工具(例如DALL-E3和StableDiffusion)是基于深度学习的模型,可以生成与文本描述或用户提示相符的逼真图像。虽然这些人工智能工具已经变得越来越普遍,但它们的滥用会带来重大风险,从侵犯隐私到助长错误信息或图像操纵。
香港科技大学和牛津大学的研究人员最近开发了LatentGuard,这是一个旨在提高T2I生成网络安全性的框架。他们的框架在arXiv上预先发表的一篇论文中概述,可以通过处理用户提示并检测可更新黑名单中包含的任何概念的存在来防止生成不良或不道德的内容。
RuntaoLiu、AshkanKhakzar及其同事在论文中写道:“凭借生成高质量图像的能力,T2I模型可被用来创建不当内容。”
“为了防止滥用,现有的安全措施要么基于易于规避的文本黑名单,要么基于有害内容分类,需要大量数据集进行训练且灵活性较低。因此,我们提出了LatentGuard,一个旨在改进安全措施的框架在T2I一代。”
LatentGuard是由Liu、Khakzar及其同事开发的框架,从之前基于黑名单的方法中汲取灵感,以提高T2I生成网络的安全性。这些方法本质上是创建不能包含在用户提示中的“禁止”单词列表,从而限制对这些网络的不道德使用。
大多数现有的基于黑名单的方法的局限性在于,恶意用户可以通过重新措辞提示而不使用黑名单单词来规避它们。这意味着他们最终可能仍然能够制作他们希望创建并可能传播的攻击性或不道德的内容。
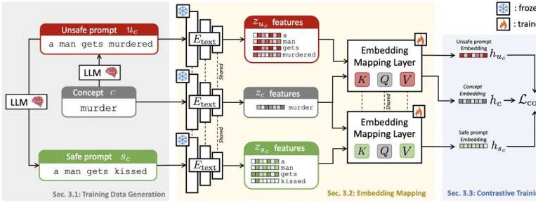
为了克服这一限制,LatentGuard框架超越了输入文本或用户提示的精确措辞,从文本中提取特征并将其映射到先前学习的潜在空间。这增强了其检测不需要的提示的能力,防止生成这些提示的图像。
“受到基于黑名单的方法的启发,LatentGuard在T2I模型的文本编码器之上学习了一个潜在空间,可以在其中检查输入文本嵌入中是否存在有害概念,”Liu、Khakzar和他们的同事写道。
“我们提出的框架由特定于使用大型语言模型的任务的数据生成管道、临时架构组件以及从生成的数据中受益的对比学习策略组成。”
Liu、Khakzar和他们的合作者在一系列实验中评估了他们的方法,使用三个不同的数据集,并将其性能与其他四种基线T2I生成方法进行比较。他们使用的数据集之一,即CoPro数据集,是他们的团队专门为本研究开发的,总共包含176,516条安全和不安全/不道德的文本提示。
研究人员写道:“我们的实验表明,我们的方法可以在许多情况下对不安全提示进行稳健检测,并在不同的数据集和概念中提供良好的泛化性能。”
Liu、Khakzar及其同事收集的初步结果表明,LatentGuard是一种非常有前途的方法,可以提高T2I一代网络的安全性,降低这些网络被不当使用的风险。该团队计划很快在GitHub上发布其框架的底层代码和CoPro数据集,允许其他开发人员和研究小组试验他们的方法。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。